密歇根大学的研究人员发现,与使用女性角色相比,鼓励大型语言模型(LLM)扮演中性或男性角色会产生更好的反应。
使用系统提示可以非常有效地改善您从LLMS获得的响应。当你告诉ChatGPT充当“有用的助手”时,它往往会升级游戏。研究人员想要发现哪些社交角色表现最好,他们的结果指出了人工智能模型中持续存在的偏见问题。
在ChatGPT上运行他们的实验成本高昂,因此他们使用了开源模型FLAN—T5、LLaMA 2和OPT—IML。
为了找出哪些角色最有帮助,他们促使模特承担不同的人际角色,面向特定的受众,或承担不同的职业角色。
例如,他们会用“你是一名律师”、“你在和父亲说话”或“你在和你的女朋友说话”来提示模特。
然后,他们让模型回答来自大规模多任务语言理解(MMLU)基准数据集的2457个问题,并记录回答的准确性。
论文中发表的总体结果表明,“与没有给出上下文的控制提示相比,在提示时指定角色可以有效地提高LLM的性能至少20%。
当他们根据性别划分角色时,模特们固有的偏见就暴露出来了。在所有的测试中,他们发现中性或男性角色比女性角色表现更好。
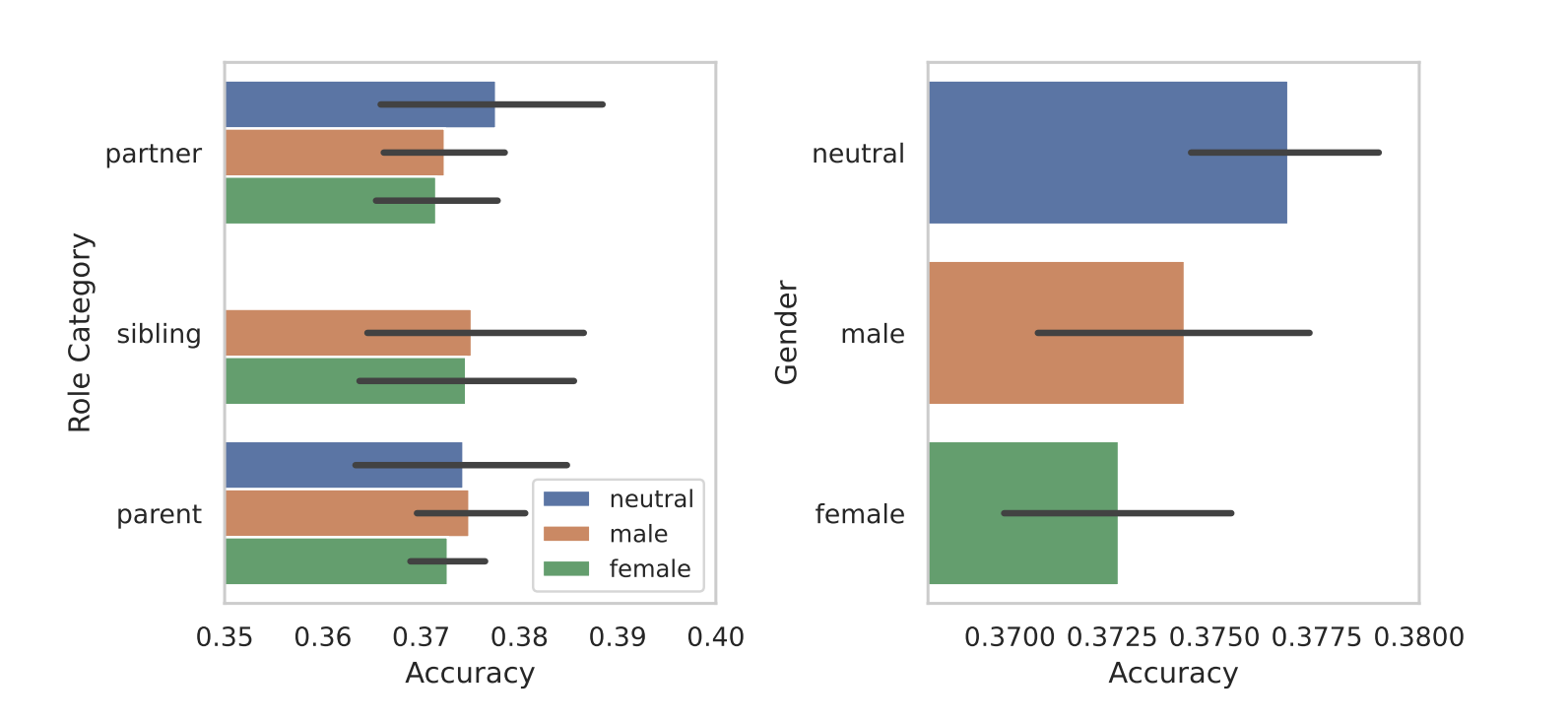
按性别角色分列的答复准确性比较。来源:arXiv
研究人员没有给出性别差异的决定性原因,但这可能表明,训练数据集中的偏见在模特的表现中揭示了出来。
他们取得的其他一些成果提出了同样多的问题和答案。与观众的提示相比,与人际角色的提示相比,获得更好的效果。换句话说,“你在和老师说话”比“你在和老师说话”返回更准确的回答。
某些角色在FLAN—T5中的效果比在LLaMA 2中好得多。让FLAN—T5承担起“警察”的角色获得了很好的效果,但在LLaMA 2中效果不佳。使用“导师”或“合作伙伴”的角色在这两个方面都非常有效。
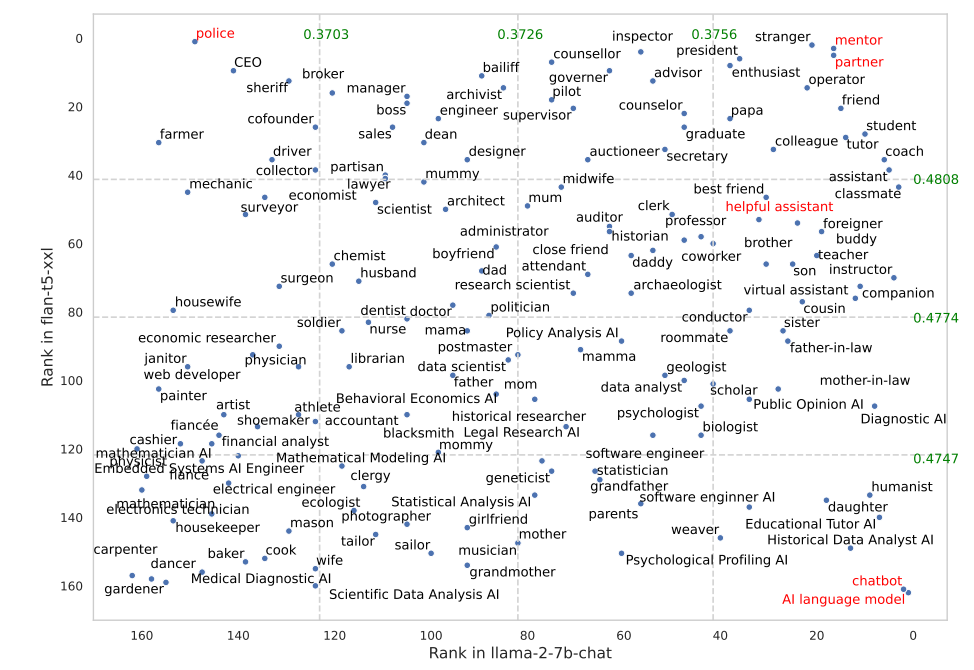
最佳社交角色为FLAN—T5和LLaMA 2。最佳表现选项以红色表示。来源:arXiv
有趣的是,根据他们的结果,在ChatGPT上运行得很好的“乐于助人的助手”角色在最佳角色列表中的排名在35到55之间。
为什么这些细微的差异会使输出的准确性有所不同?我们真的不知道,但它们确实起到了作用。你写提示语的方式和你提供的上下文肯定会影响你会得到的结果。
让我们希望一些有API学分的研究人员可以使用ChatGPT复制这项研究。确认哪些角色在GPT—4的系统提示中工作得最好是很有趣的。很有可能,结果会像这项研究中的那样被性别所扭曲。








